Project Summary
Comprehensive comparison of deep learning models and traditional machine learning on image classification tasks.
ResNet Classification Results
Grid search over batch sizes, optimizers, and learning rates for ResNet-18 and ResNet-50.
Best MNIST
ResNet-18Adam optimizer, lr=0.001, batch_size=16
Best FashionMNIST
ResNet-18Adam optimizer, lr=0.001, batch_size=32
MNIST Dataset - Test Classification Accuracy (%)
| Batch Size | Optimizer | Learning Rate | ResNet-18 | ResNet-50 |
|---|---|---|---|---|
| 16 | SGD | 0.001 | 98.95 | 98.55 |
| 16 | SGD | 0.0001 | 98.48 | 97.91 |
| 16 | Adam | 0.001 | 99.01 | 98.31 |
| 16 | Adam | 0.0001 | 98.76 | 97.74 |
| 32 | SGD | 0.001 | 98.82 | 98.70 |
| 32 | SGD | 0.0001 | 97.91 | 96.87 |
| 32 | Adam | 0.001 | 98.78 | 98.54 |
| 32 | Adam | 0.0001 | 98.66 | 97.02 |
FashionMNIST Dataset - Test Classification Accuracy (%)
| Batch Size | Optimizer | Learning Rate | ResNet-18 | ResNet-50 |
|---|---|---|---|---|
| 16 | SGD | 0.001 | 90.06 | 89.02 |
| 16 | SGD | 0.0001 | 88.66 | 85.60 |
| 16 | Adam | 0.001 | 90.57 | 87.42 |
| 16 | Adam | 0.0001 | 89.35 | 87.91 |
| 32 | SGD | 0.001 | 89.93 | 89.29 |
| 32 | SGD | 0.0001 | 87.86 | 83.60 |
| 32 | Adam | 0.001 | 90.76 | 89.40 |
| 32 | Adam | 0.0001 | 89.69 | 86.91 |
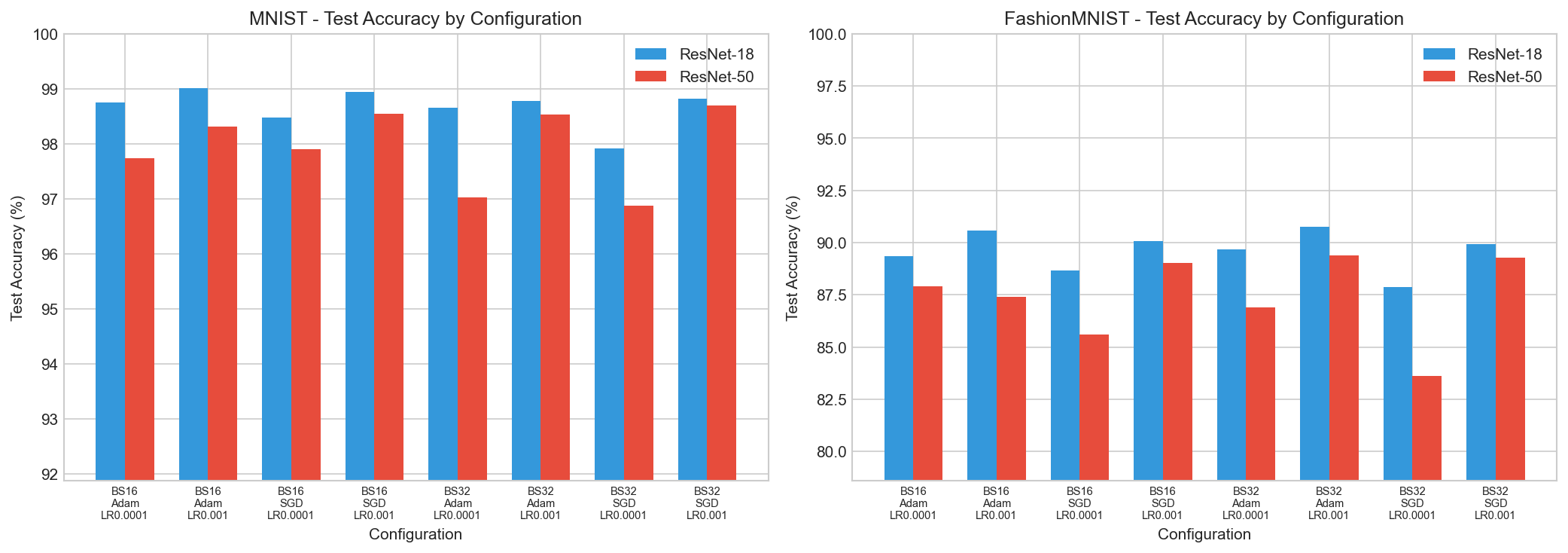
Accuracy Comparison
Test accuracy across all configurations
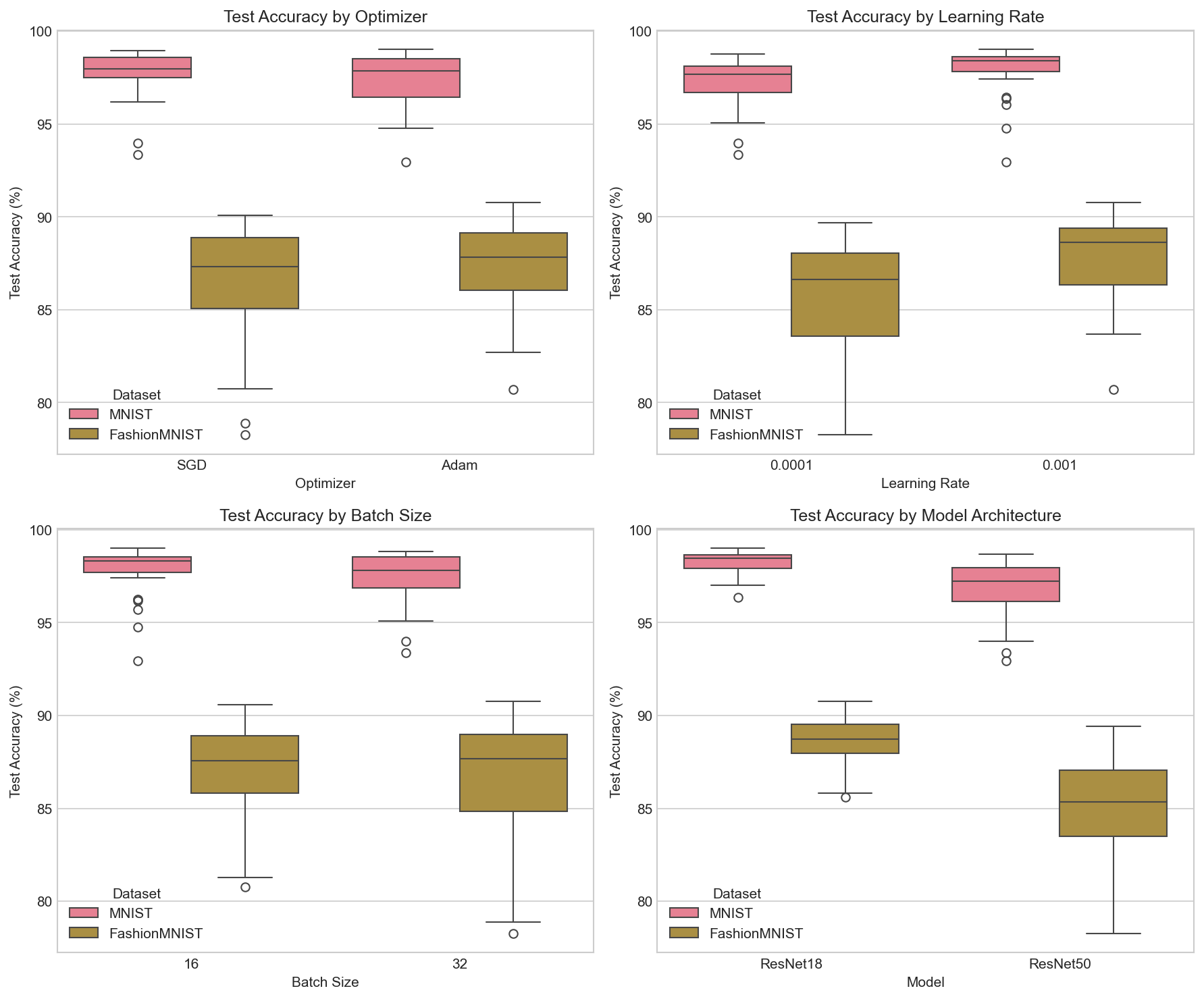
Hyperparameter Analysis
Impact of different hyperparameters
SVM Classification Results
Support Vector Machine with Polynomial and RBF kernels.
Best MNIST SVM
RBF KernelC=10.0, gamma=scale
Best FashionMNIST SVM
RBF KernelC=10.0, gamma=scale
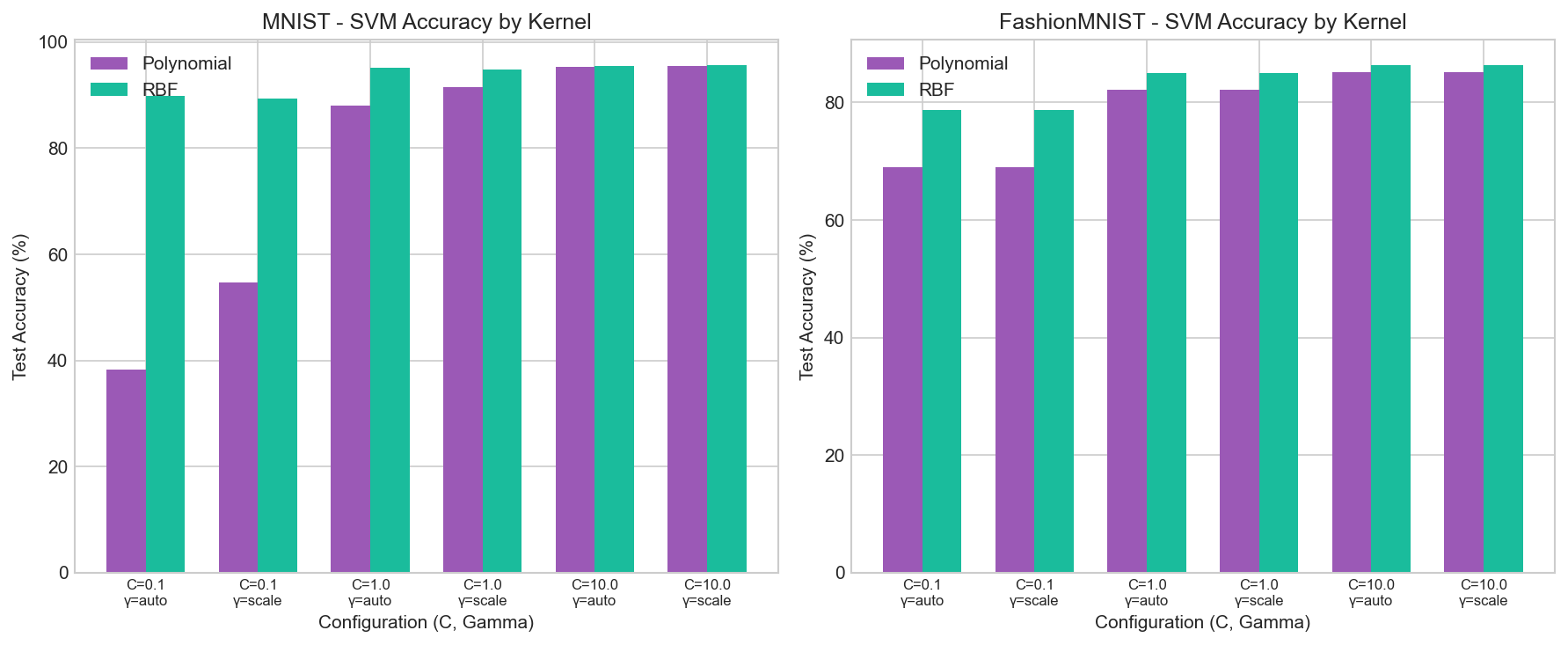
SVM Accuracy by Kernel
Comparison of polynomial vs RBF kernels
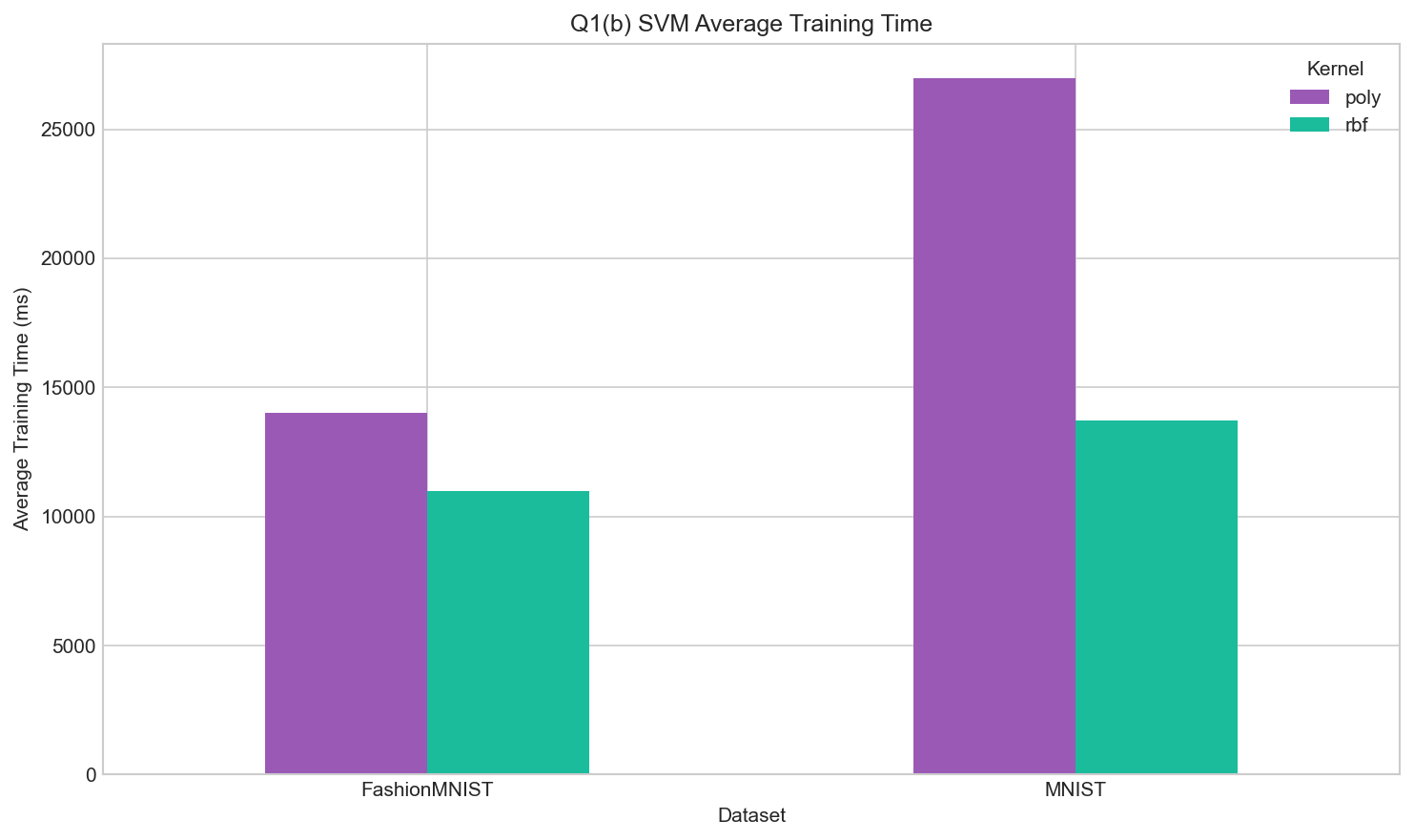
SVM Training Time
Training efficiency across configurations
CPU vs GPU Performance
Training time and accuracy comparison between CPU and CUDA.
CPU vs GPU Training Comparison (FashionMNIST)
| Compute | Model | Optimizer | Accuracy (%) | Training Time (ms) | FLOPs |
|---|---|---|---|---|---|
| CPU | ResNet-18 | SGD | 88.54 | 341,621 | 33.18M |
| CPU | ResNet-18 | Adam | 88.23 | 470,803 | 33.18M |
| CPU | ResNet-50 | SGD | 84.84 | 1,064,108 | 78.76M |
| CPU | ResNet-50 | Adam | 87.11 | 1,281,028 | 78.76M |
| CUDA | ResNet-18 | SGD | 87.97 | 62,967 | 33.18M |
| CUDA | ResNet-18 | Adam | 86.14 | 69,794 | 33.18M |
| CUDA | ResNet-50 | SGD | 84.18 | 111,651 | 78.76M |
| CUDA | ResNet-50 | Adam | 86.96 | 125,693 | 78.76M |
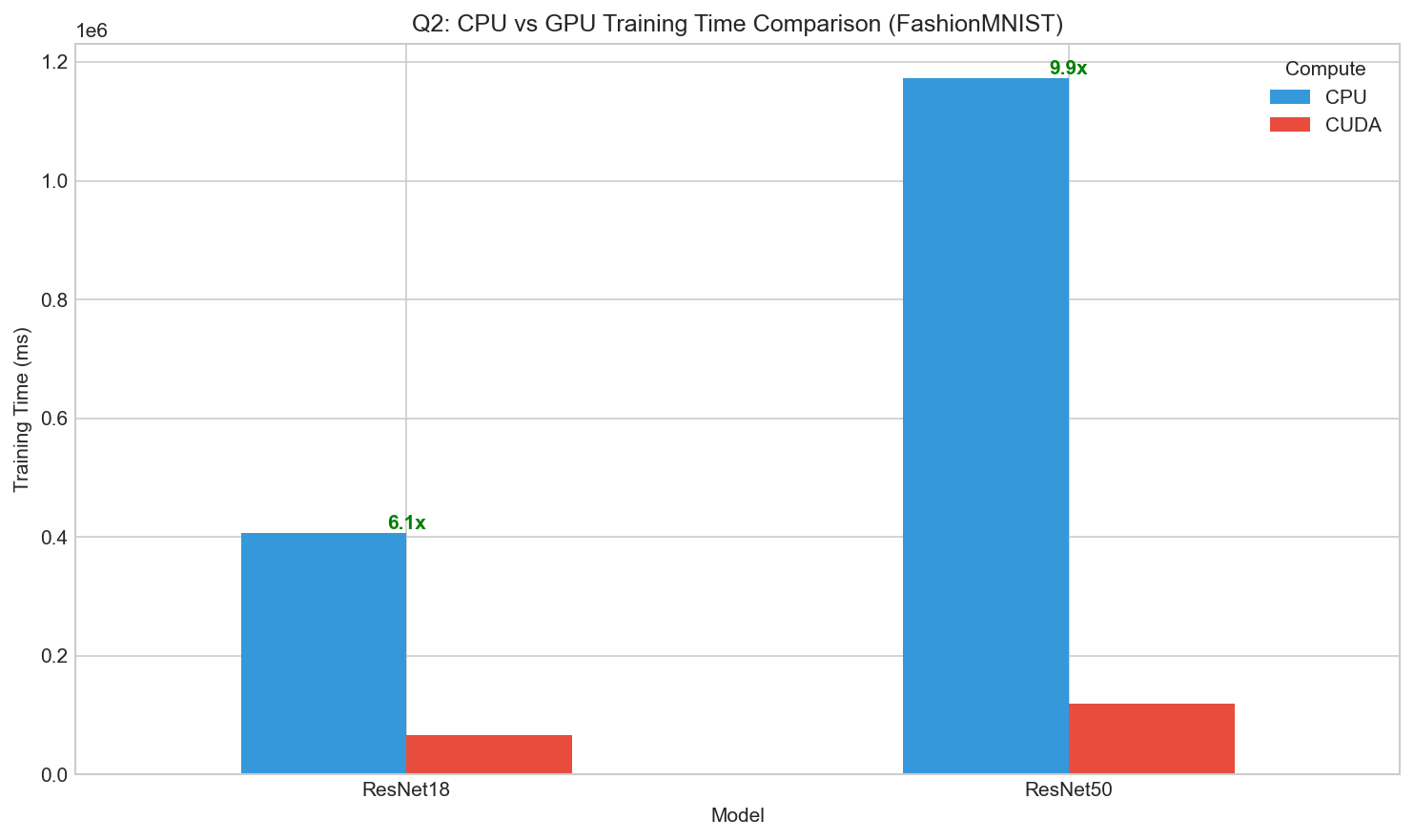
Training Time Comparison
CPU vs GPU training speed with speedup factors
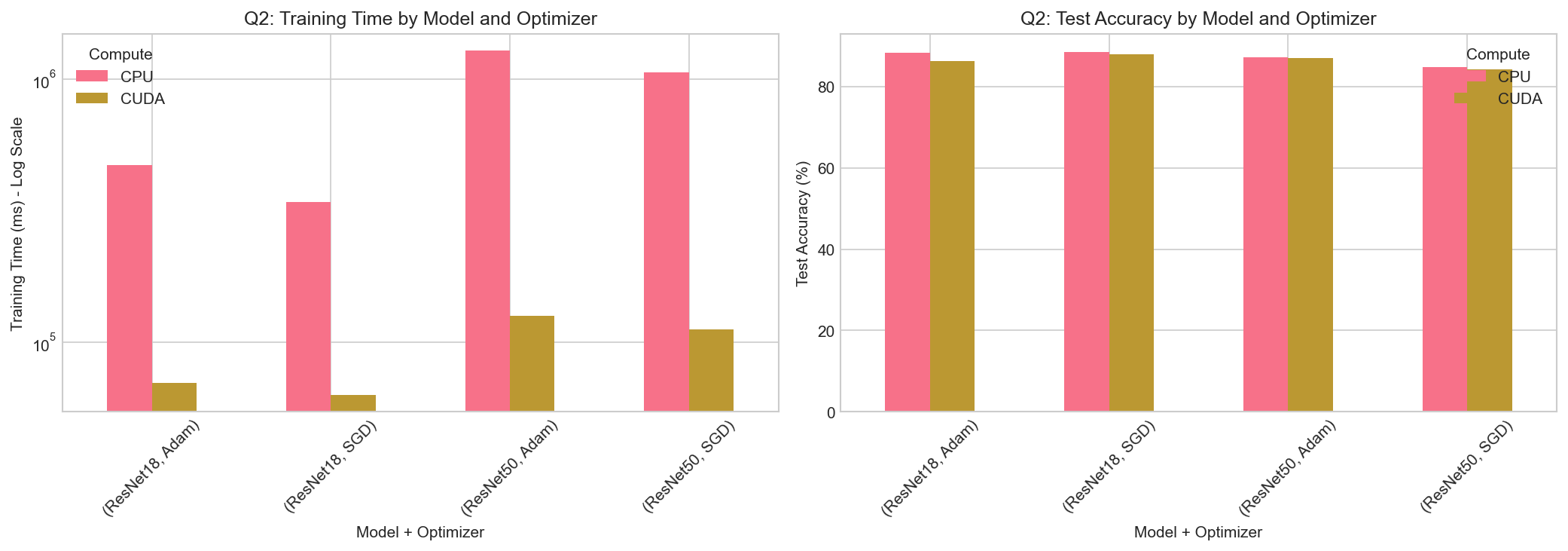
Combined Results
Time and accuracy by model and optimizer
Key Findings
Important insights from the experiments.
Model Architecture
ResNet-18 consistently outperforms ResNet-50 on both datasets. Smaller models generalize better on relatively simple datasets, while larger models may overfit.
Optimizer Choice
Adam optimizer achieves higher accuracy than SGD in most configurations. It converges faster and is less sensitive to learning rate choices.
Learning Rate
lr=0.001 generally produces better results than lr=0.0001, enabling faster convergence within limited epochs.
GPU Acceleration
GPU provides 5-10x speedup over CPU, with larger speedups for bigger models. Mixed precision training further improves performance.
DL vs ML
Deep learning (ResNet) significantly outperforms traditional SVM: 99.01% vs 95.60% on MNIST, 90.76% vs 86.30% on FashionMNIST.
Batch Size
Smaller batch sizes (16) provide more regularization, while larger batches (32) offer better GPU utilization and stability.
Best Models
Overall Best Results
| Task | Dataset | Model | Configuration | Accuracy |
|---|---|---|---|---|
| Q1(a) | MNIST | ResNet-18 | Adam, lr=0.001, bs=16 | 99.01% |
| Q1(a) | FashionMNIST | ResNet-18 | Adam, lr=0.001, bs=32 | 90.76% |
| Q1(b) | MNIST | SVM (RBF) | C=10.0, gamma=scale | 95.60% |
| Q1(b) | FashionMNIST | SVM (RBF) | C=10.0, gamma=scale | 86.30% |